PGAN 训练笔记
1 | /path/to/database = /big_data/hsj/ParallelWaveGAN/egs/aishell3/wav |
- 目前使用的是,所有 AiShell3数据集,但是用的是 single_speaker 的代码
- 数据的处理用到了 sklearn.StandardScaler 的 「均值、方差」归一化,(对训练集),所以咱们StarGAN-vc2中也暂时不自己写 数据预处理的环节了,用他处理好的 .npy 来读取,然后再做 【截取固定帧数】的操作
StarGAN-VC2 一些参数:
- batch_size=8
- learning_rate_G = 0.0002 | learning_rate_D = 0.0001
- 每条句子切成 :128 帧
- 22050Hz
- 34 维度 sp
- 帧移: 5ms


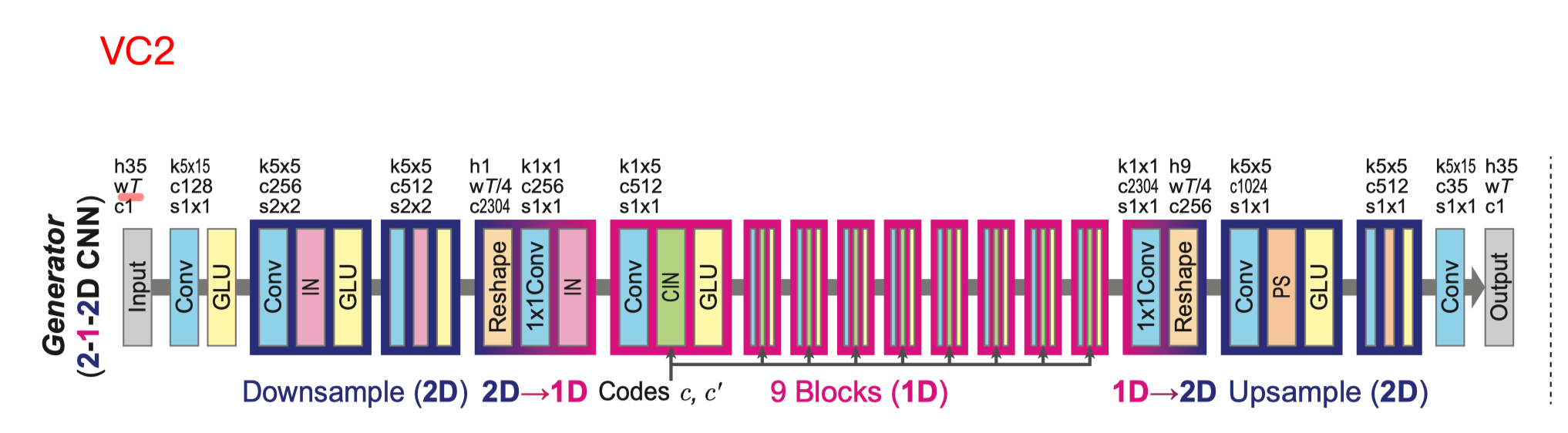
VC 2 结构:

VC 1 结构
Torch官方算卷积的公式
https://pytorch.org/docs/master/generated/torch.nn.Conv2d.html#torch.nn.Conv2d


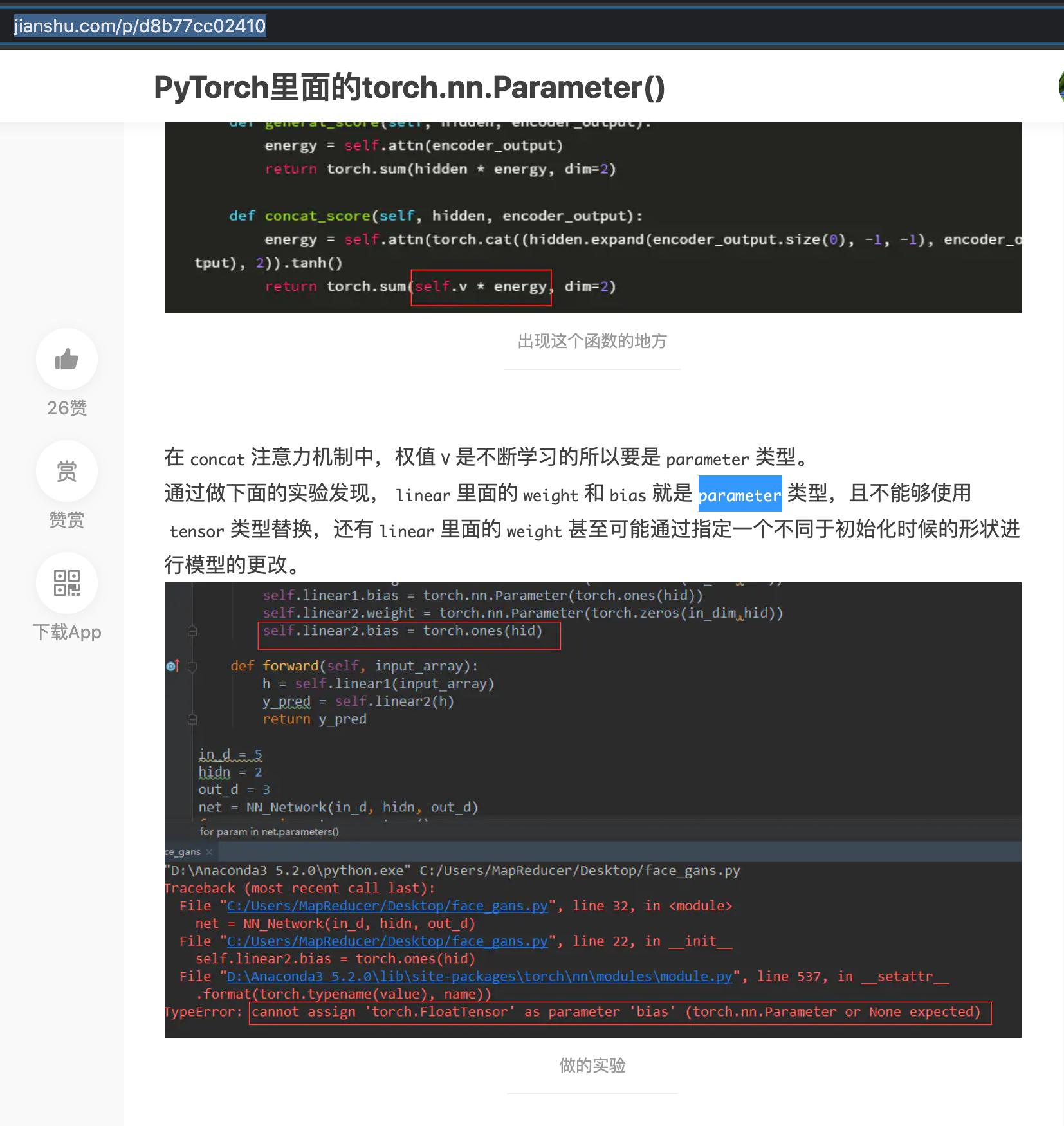
https://www.jianshu.com/p/d8b77cc02410
Tensorflow 版本的 CIN
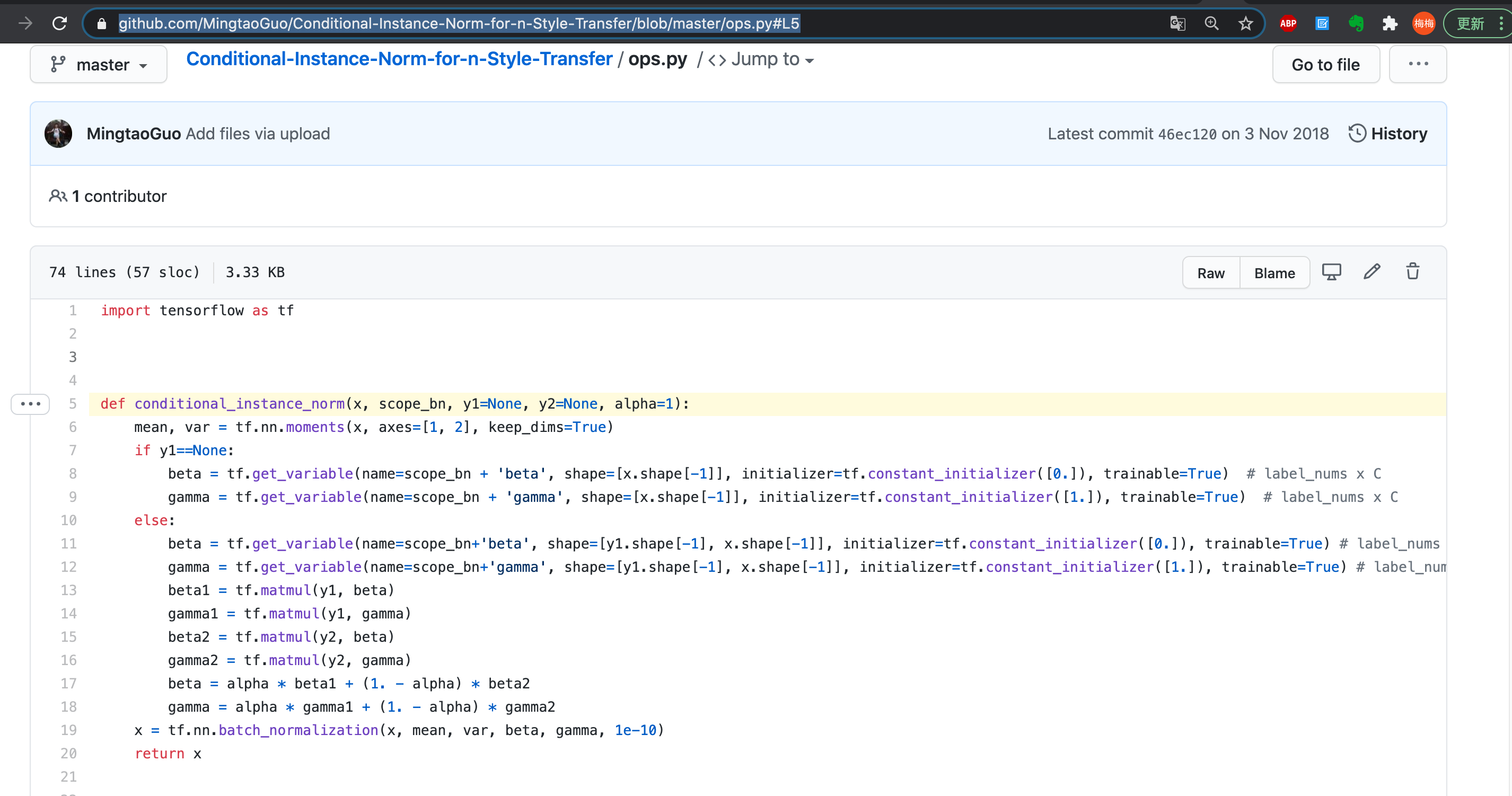
参考这两份:
- Torch:https://github.com/ChinmayLad/neural-style-transfer/blob/dc44cd261fd9bdf684440ef104cec65fe5be15c5/normalization.py
- TensorFlow:https://github.com/MingtaoGuo/Conditional-Instance-Norm-for-n-Style-Transfer/blob/master/ops.py#L5
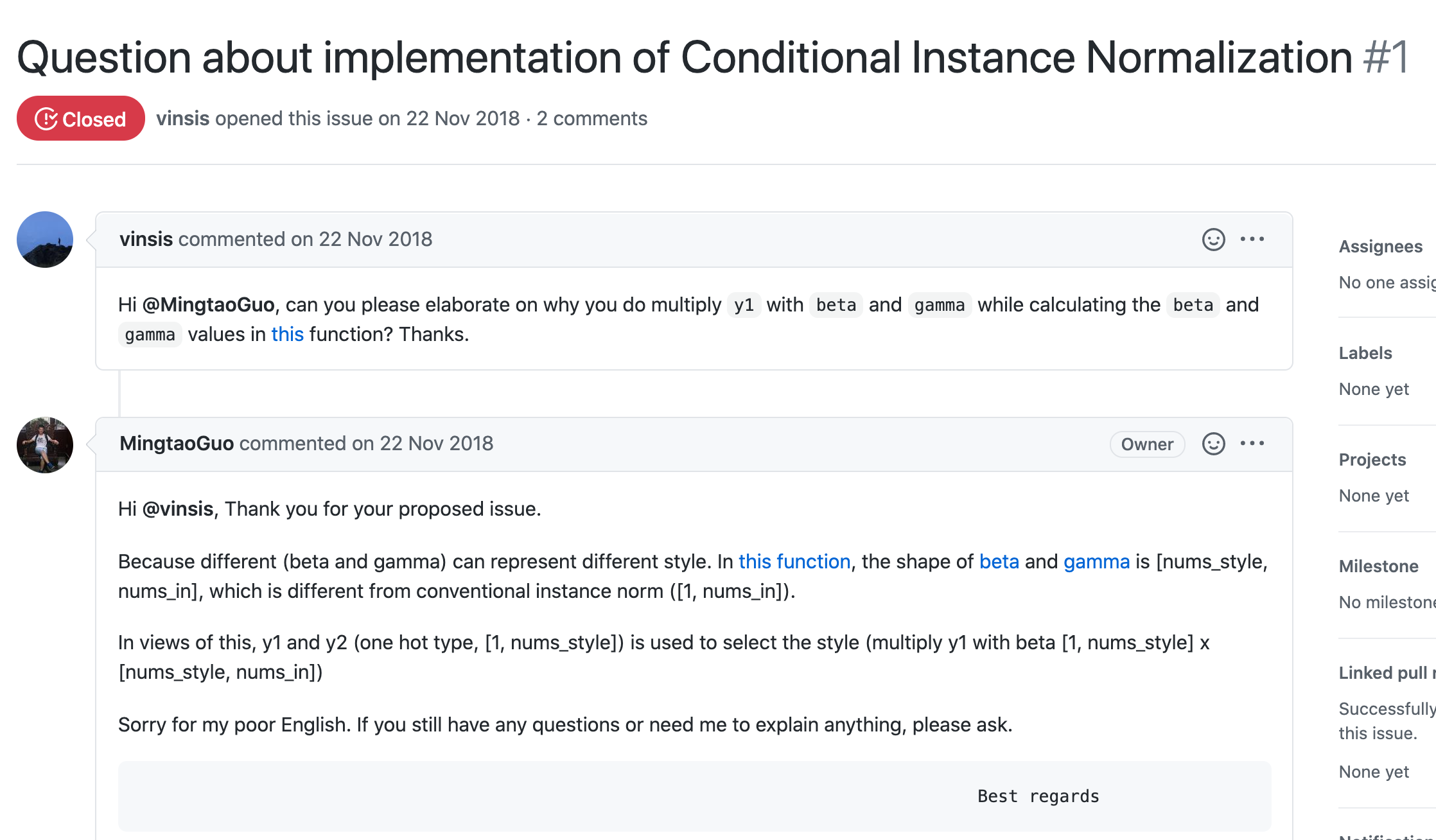
- 对应回答 issue
1211:
CIN 个人理解:
输入:one-hot = 【1,0,0,0,】 ;特征 x =【8,512,32】=【batch, channel=每个单词用多少特征来表示俄mbedding, 句子长度=含有32个单词】
过程:
- 先是构造一张特征表,尺寸为【说话人数目 / 特征种类, 每个说话人 用多少维度的embedding 来表示 / 每个单词的特征通道数「一维角度来看」】 = 【4, 512】
- 然后,用对应的一个说话人的 one-hot 来取这张表上的特征值 【1,num_styles=4】x【num_styles=4,num_in=特征数=512】
- 在这个过程中,我们用Torch实现时,可以用 $nn.linear()$ 函数(看作全连接)来表示矩阵乘法:nn.linears(in_channel = 4, out_channel = 512)——nn.linear()中的参数是可训练的!会加入到整张图的参数列表中去
- 然后把 one-hot 特征送进全连接网络,得到对应的一个特征【512维】,$\gamma$ 和 $\beta$ 都是这么处理的
- 最后 , 两个特征参数,和前面送进来的并经过 均值 & 归一化 处理过的 x ,相互配合起来,得到当前层的 CIN 结果

关于PixelShuffle
- https://blog.csdn.net/g11d111/article/details/82855946
- https://blog.csdn.net/u014636245/article/details/98071626
- https://pytorch.org/docs/0.3.1/_modules/torch/nn/modules/pixelshuffle.html
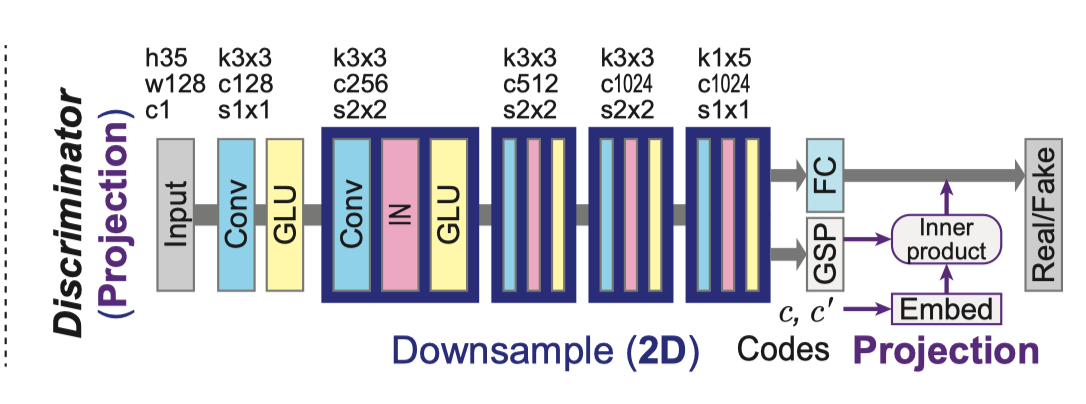
关于 GSP:global sum pooling
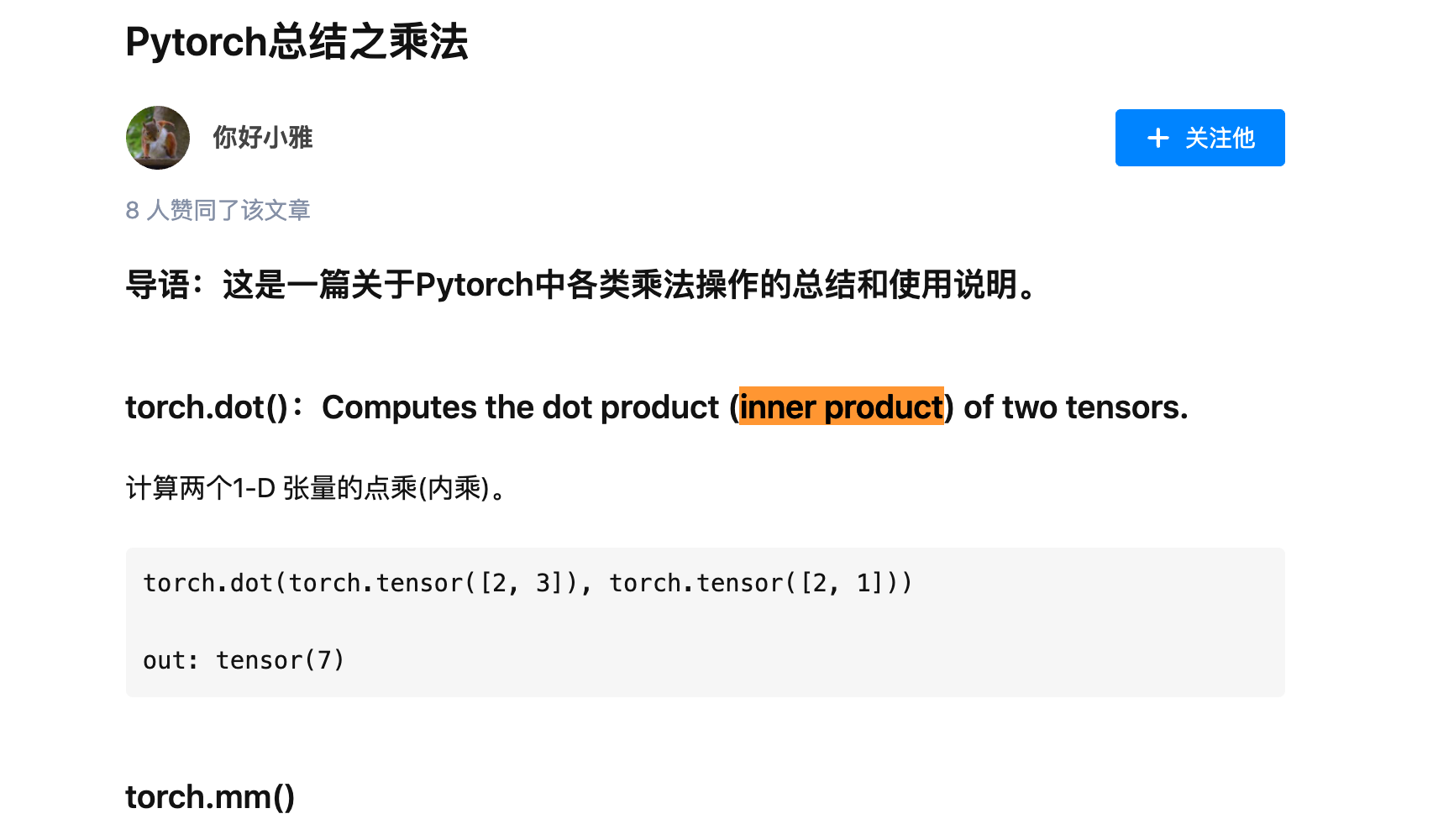
关于 inner product 向量内积 https://zhuanlan.zhihu.com/p/212461087
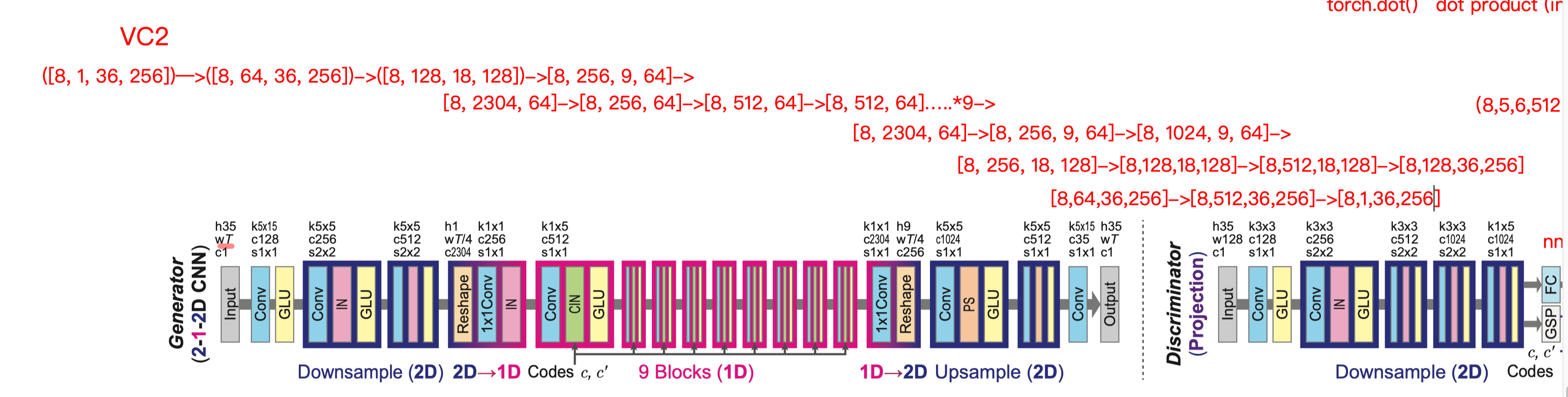
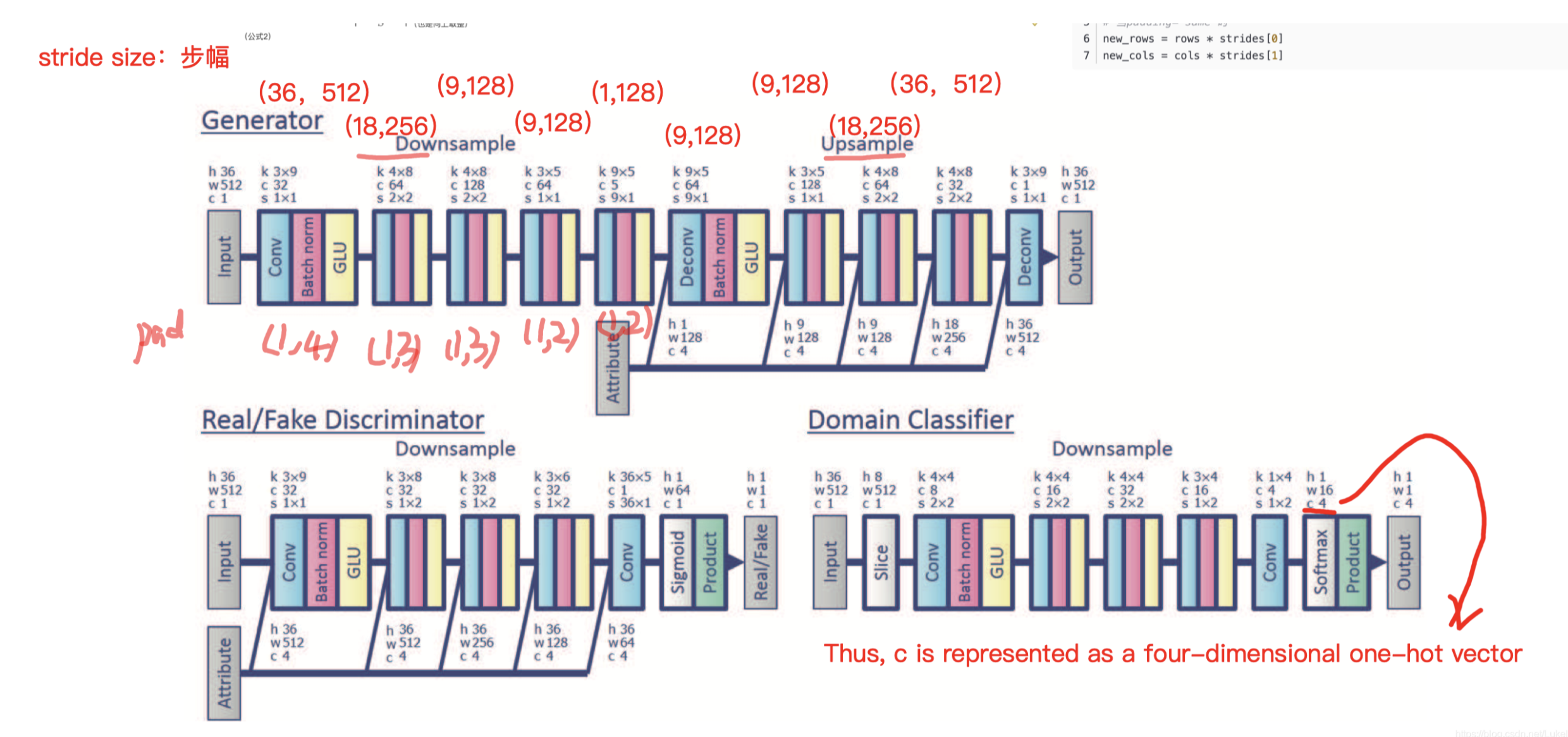
整个模型 尺寸信息:
- 原本 Generator 尺寸: