0920-论文总结

2020.09.20
本周完成的工作:
(写了比较多的验证实验代码,助于理解原理)
学习掌握了 LMDB 格式数据的处理(创建/插入/读取/修改)
实现了 Numpy 类型数据转 lmdb(librosa提取出来的mel数据需要处理成 连续存储 np.ascontiguousarray())
从 lmdb 读取数据,并转换成 numpy(np.fromstring(value, dtype=np.float32)),并完整复原成语音。
Mel —>(griffin)—>wav:对比试验了几个版本的 tacotron 的语音数据处理代码, 结合网上资料,总结一套转换效果质量较好的 代码:(mag -> mel ; mel -> mag; mag ->wave)【很多资料版本在借用griffin实现 mel 转 幅度谱 mag 环节,写的不够好甚至没写清楚】
数据处理环节:NVAE 中的 图像处理是【n,n】,所以采用 【256帧,n_mels=256】的参数来提取 mel(80 维的griffin复原效果太差
🌟NVAE图像**训爆了:和作者联系,问题定位在 batch太小(原32,咱们用 4【GPU限制】)情况下,learning_rate太大:1e-2 改 1e-3
在epoch 5 掉链子:warm_up环节刚过,学习率有变,所以导致数据算成了 NAN;模型保存也只保存到 epoch 1,改部分代码,先 一个epoch一个epoch保存 ckpt
可改进:
- 晚上先试着跑起来
- 后面尝试改进 NVAE 代码成 自适应 数据尺寸【m,n】(m != n)
- 在tensorboard上看下怎么展示中间步骤语音 .wav
论文涉猎
情感语音转换(TTS + VC 多任务学习)
VC领域 痛点:保存语言信息,情感信息 和 多对多VC方面,VC的性能仍然很差
解决的问题:在 2017 年一篇 “情感VC转换” 基础上,提升“转换后内容保留程度”(即,降低WER)(retaining linguistic contents)
- 有提供源码,缺 demo 展示(文件夹下载需代理,网速极其慢, 300+m 大小 / 3kb/s)


- 最新的 VC 思路是 序列到序列(Sequence 2 Seq),但是容易丢失语音信息
- 可以通过文本监督来矫正:
- 但是对齐是个问题;
- 另外这样也失去了 S2S 的优势了
- 可以通过文本监督来矫正:
- 本文思路:
- 利用 多任务学习的 TTS 模型,来帮助 VC 模型 捕获语言信息并保持训练稳定性。
- TTS 框架来源 tacotron(有局部的稍微改动):(Style Encoder 也是借鉴这篇)

- VC 框架:另外并联一个 “Content Encoder”
要点:
- 并不像传统做 情感转换那样,在训练阶段就提取 情感标签(one-hot形式);
- 在整个网络中,也不会将 情感标签 当作一个条件作为输入 (联想一下之前的 pitch 标签)
- 可以在单个模型中执行VC和TTS
网络结构:
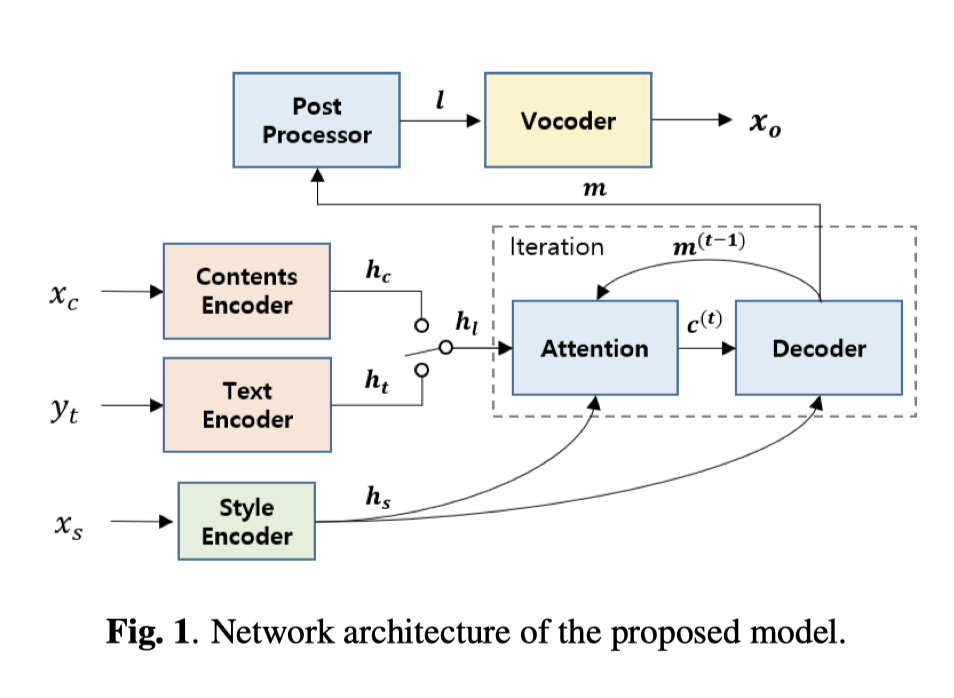
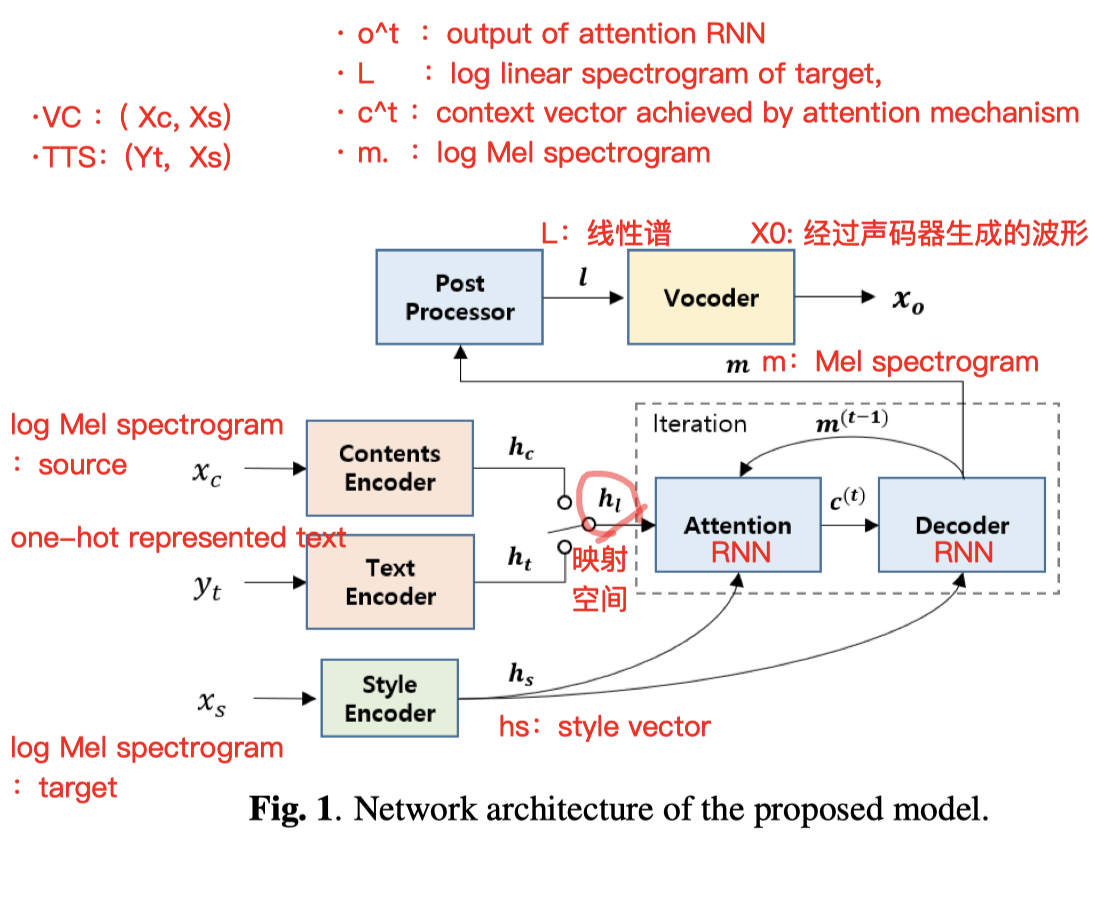

TTS 支线:(以 tacotron 为原型)
- 模仿的是:

- 框架:
- text encoder,
- decoder,
- attention,
- and post processor
- 改动:(参考 [17] 文献)
- 文字向量context vector $C_t$ 被用在 AttentionRNN 的每个循环内(context vector c (t)utilizes is used for every iteration in attention RNN)[原本是怎么样的?查一下]
- 在 CBHG (Convolution Bank + Highway + bi-GRU) 模块中,增加了 *残余连接 (residual connection) *模块
Loss

- Loss 就是直接比较: mel谱 差距 && 线性谱 差距
实验参数:
- 大体上都是和 taco 部分的语音预处理手法相似
- 数据集:
- 韩国某个30岁男子,用七种情绪,每种情绪说 3k 句;共 2.1w 句;
- 其中情感:(neutral, happiness, sadness, anger, fear, surprise, and disgust)
- 去除静音之后,共约 29.2 h
- 🌟值得一提的几点:
- 去除静音,不是像taco那样,用 librosa.effect.trim() ,而是用voice activity detection algorithm (VAD 算法:开源)
- 在做 TTS-taco-like 部分里,字符处理有特点:【在转换为 one-hot embedding 这种表示形式之前会分解为 开始,核心 和 尾声(onset, nucleus, and coda)】
- 256 character embedding, 32 dimensions for $h_c$
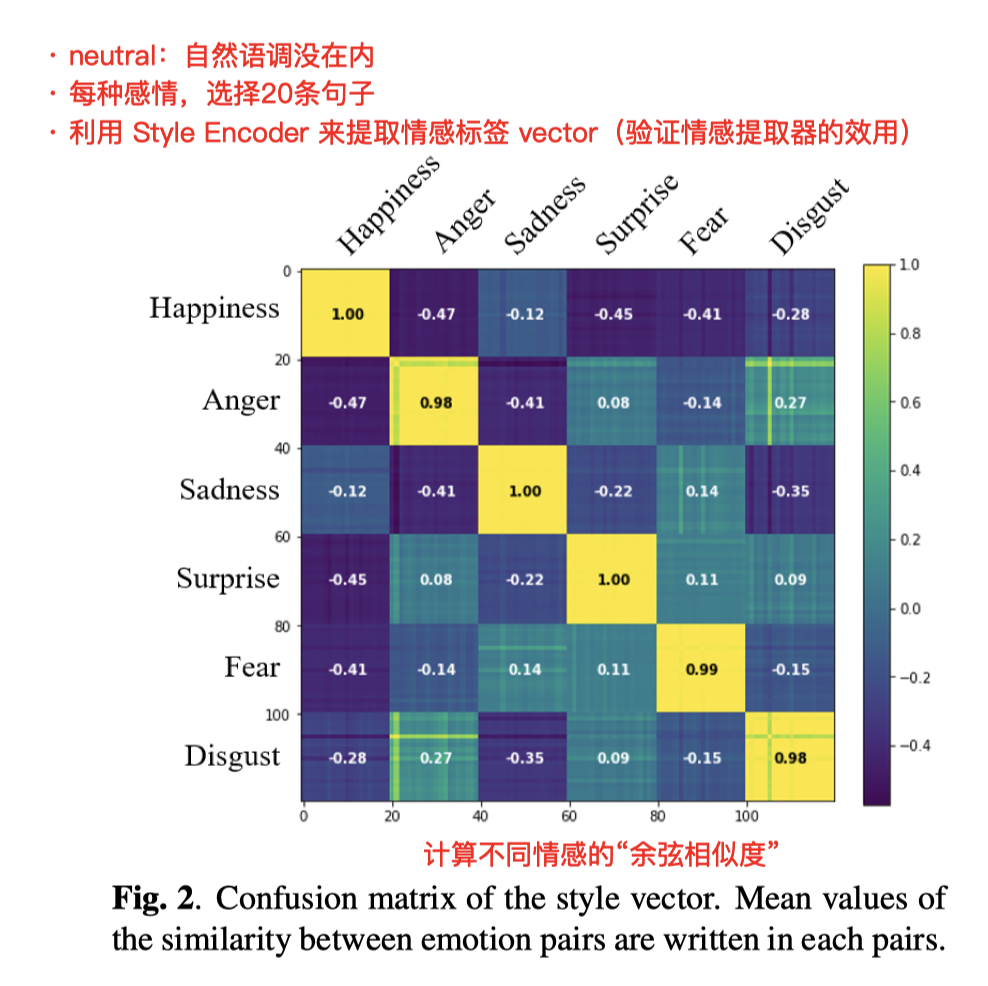
🌟重要的一个验证实验
——(内容一致性验证 Linguistic consistency)
- 每种情感 取20条句子
- 用 StyleEncoder 提取 “style vector”,并用余弦相似度来查看情感分离程度(验证情感特征提取的有效性)
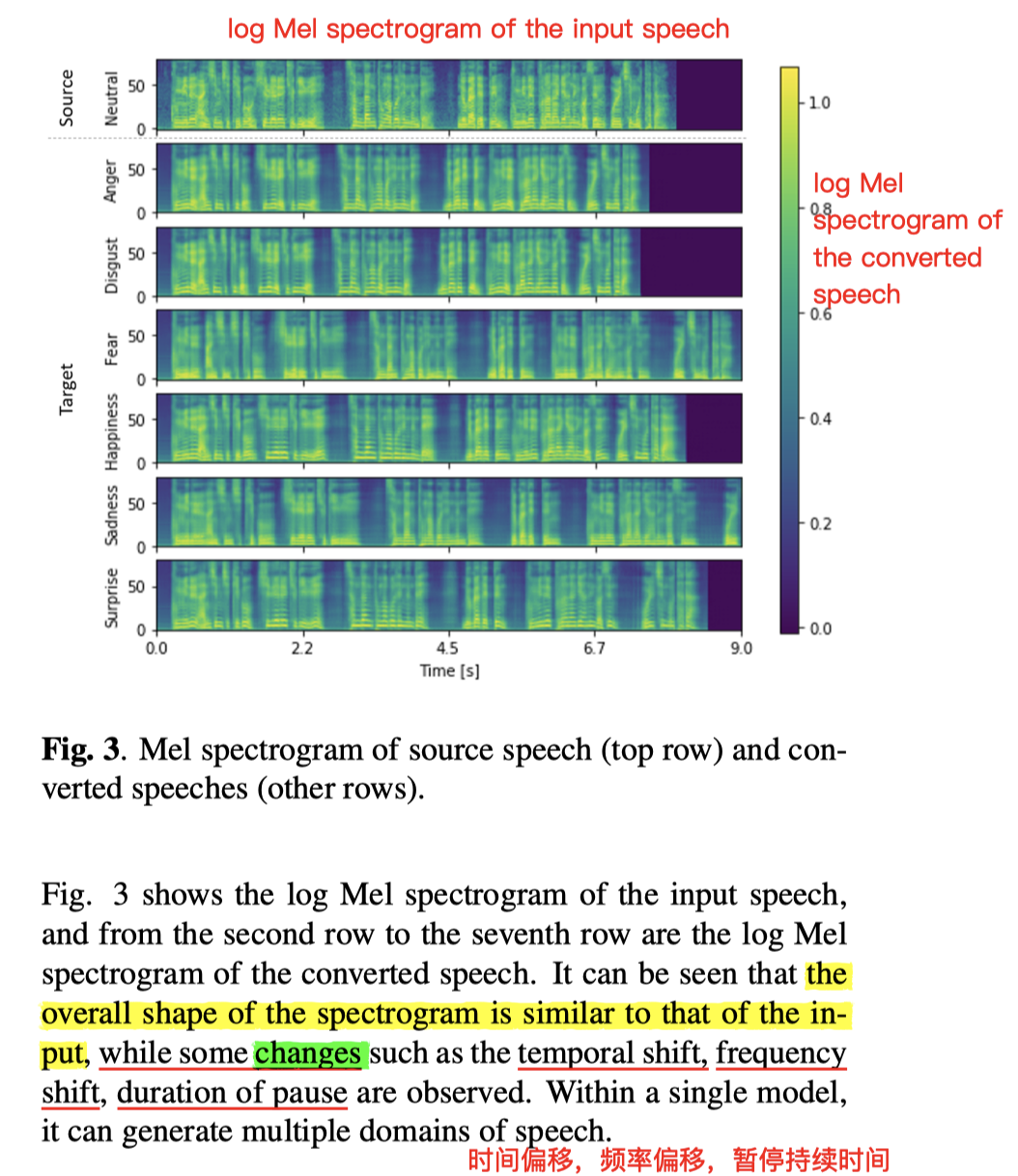
- 每种情感 句子 的内容 $X_s$ 保持不变,选取七种句子(同内容),做“从中性情感”到“其他六种情感”的转换
- 结果上看,log mel 语谱图 尺寸形状大差不差
- 有些许差异的地方:
- 时间偏移,
- 频率偏移,
- 暂停持续时间
- 总体上能实现,由一种情感,随意 VC 转换到其他情感 的能力
实验结果
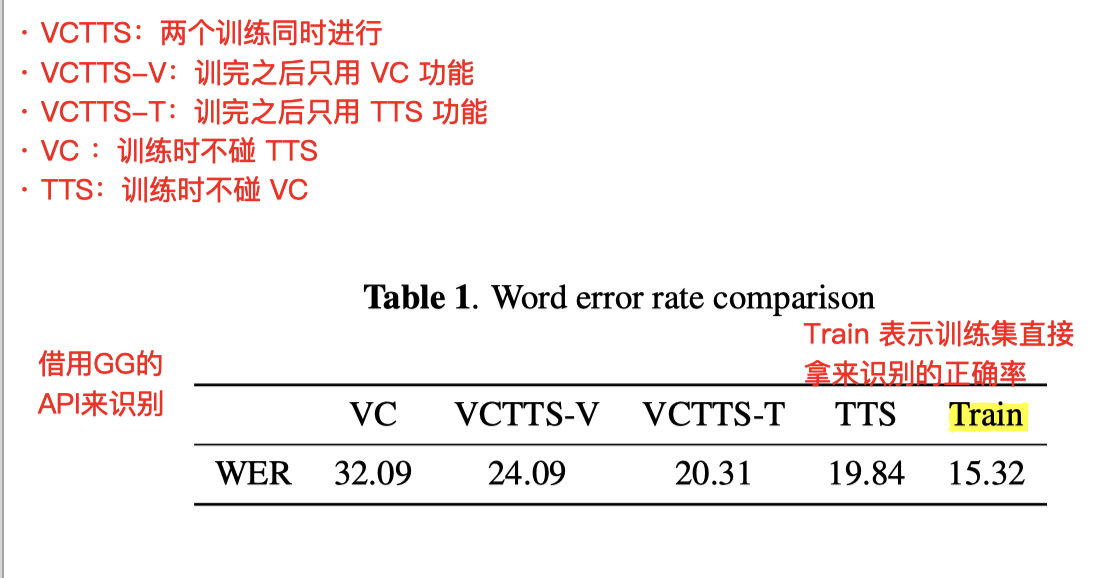
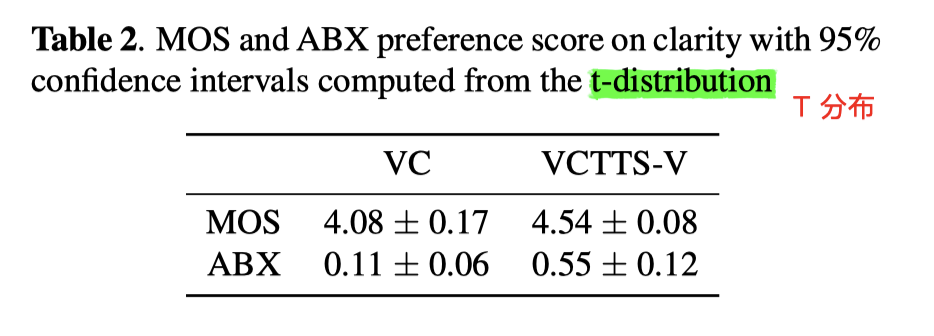
- 在联合训练的帮助下:
- VCTTS-VC 在内容保留能力上的效果,比单纯的 VC ,正确率要提高不少
- 另一方面,VCTTS-TTS 比单纯的 TTS 没有太大进步,甚至有一点点下降