0906组会分享
0906组会分享:歌唱转换 singing voice conversion

MOS评分:
- Baseline :2.92
- PitchNet:3.75

贡献:
- 利用 AE 模式下的无监督方式,解决了 平行语料的问题
- 组成模块:WaveNetlike Encoder && WaveNet autoregressive Decoder && Speaker-Embedding Table(leanable)
缺点:
- 和StarGan-VC之类的 单纯说话VC 任务不同,歌唱转换的效果重点是:说话人相似性 && 音调合理性
- BaseLine 在音调处理上差强人意,总而言之,“语音和音调的联合表示”是难点
- 走调(音高 Pitch 失控现象)问题的缓解
- 在 Baseline 的 AE无监督 模式下,附带一个额外的音调回归网络(GAN)可以将音调信息从潜在空间中分离出来
- 目的是:让原本的Encoder在单纯学习 说话人无关的语言信息 基础上,再额外剥离掉 音高信息 (not only singer-invariant but also pitch-invariant representation)
- 至于音高信息,当成一个独立问题来解决:设立独立模块来提取 source 的音高信息,以此配合 Decoder ,来操控 生成语音 的音高
- (根据作者相关 Git 项目下的 issue 讨论,这部分工作借用 Kaldi 来完成)
- 【实现 音高可控性 】
模型
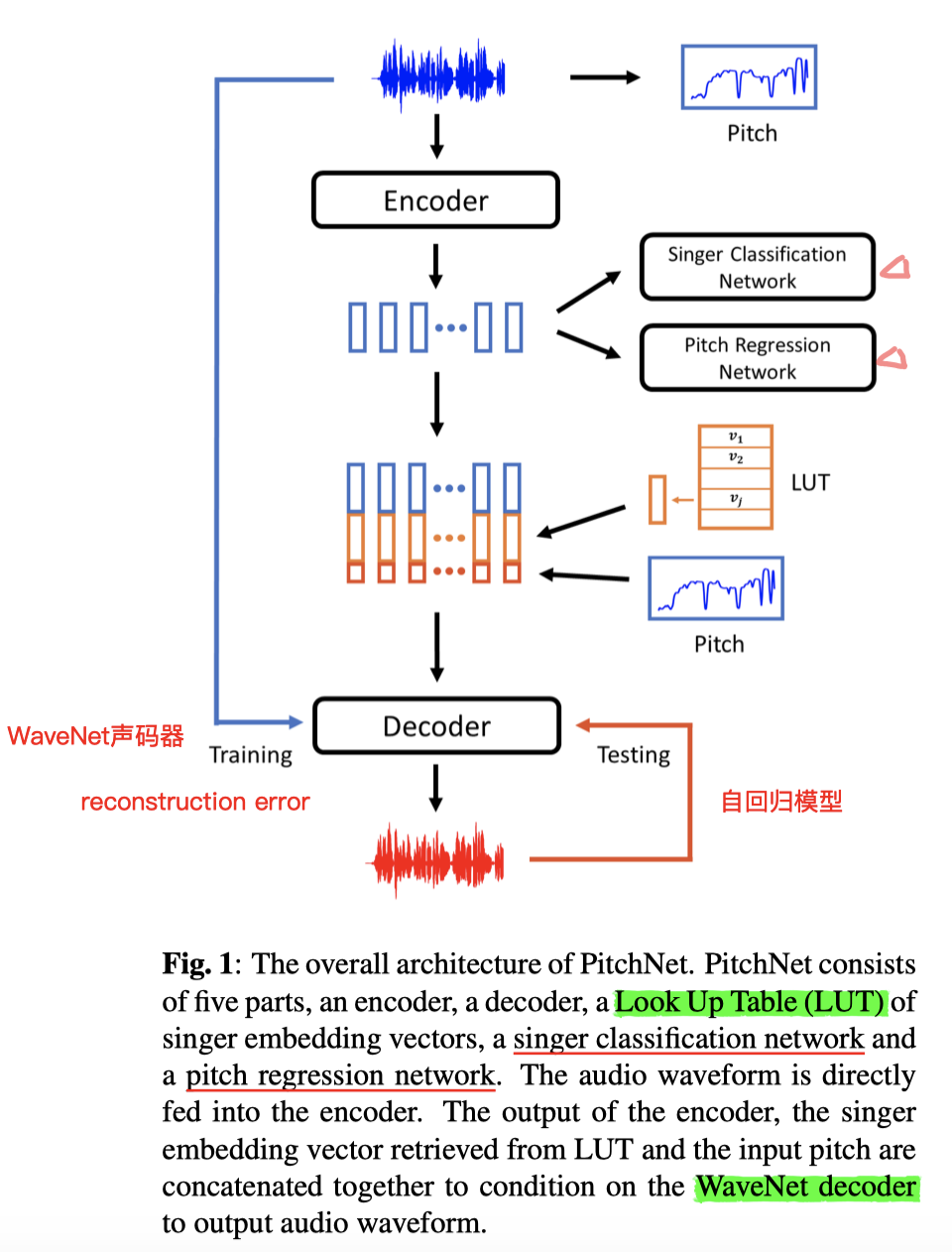
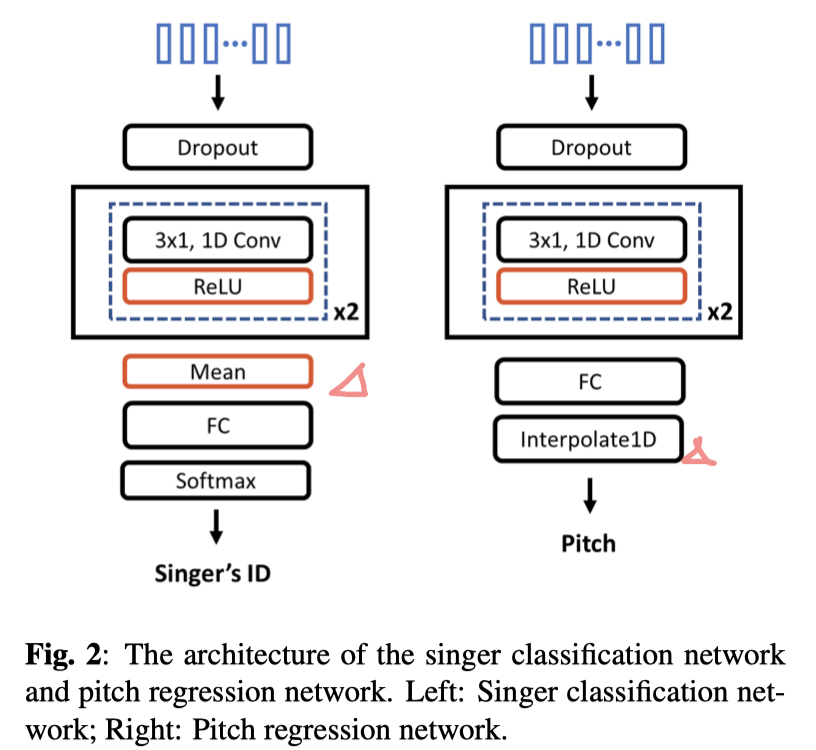
- Singer Classification Network Pitch Regression Network 是为了使得 Encoder 能够在抽取特征向量 z 时,把 说话人信息 && 音调信息 都剥离掉
Training Loss:三个Loss
- singer classification loss
- pitch regression loss
- reconstruction loss
几个公式的清晰理解:

- 说明了AE网络的Decoder产生结果 所需要的输入元素(Encoder结果+Kaldi抽取的音高+Embedding信息)
- 介绍重构损失:在Decoder时配合source的embedding,和source语音做Loss

- 一个 说话人分类器,同理为 StarGan-VC 的Domain-Classification,分类对象,是Encoder结果&&Embedding
- 另一个音高分类器,Pitch信息由 Kaldi 提取
- 总的Loss结构:因为重构损失⬇️越好,另一方面,对于两个分类器,我们希望我们的 Encoder提取出来的隐变量 能彻底剥离 说话人信息 && Pitch信息,所以这两个的误差,对于结果来说,应该越大越好。(所以这两个部分是配合 负号)
- 上述两个 C分类器的损失,对于Encoder和Classifier来说,是完全相反的,【就是典型的GAN对抗思路】,所以他们的训练,采取“你一次我一次的过程”
- 训练中,缩小 $$L_{total}$$ 时,促进的是 Encoder 将两个元素剥离
- 缩小 $L_{ad}$ 时,促进的是 Classifier 具有更强的分类能力,能看透隐变量 z 的实质和归属
Ps.整体思路比较清晰,就是自回归那个部分不知道是怎么具体实现的
Quantitative and Qualitative Experiments**【定量 和 定性 实验】
Tencent :LPCNet,
1 | python convert_tfrecord_to_lmdb.py --dataset=celeba --tfr_path=/data/hsj/NVAE/DATA_DIR/celeba/celeba-tfr --lmdb_path=/data/hsj/NVAE/DATA_DIR/celeba/celeba-lmdb --split=train |
1 | export EXPR_ID=/data/hsj/NVAE/EXPR_ID |
1 | CelebA64 数据预处理 |
1 | python create_celeba64_lmdb.py --split train --img_path ../DATA_DIR/celeba_org/celeba --lmdb_path ../DATA_DIR/celeba64_lmdb |
1 | python convert_tfrecord_to_lmdb.py --dataset=celeba --split=validation |
1 | python train.py --data $DATA_DIR/celeba64_lmdb --root $CHECKPOINT_DIR --save $EXPR_ID --dataset celeba_64 \ |
/Users/huangshengjie/Desktop/NVAE/scripts/data1/datasets/imagenet-oord