展示demo:https://liusongxiang.github.io/end2endAC/
- 是在 VC 之上,再做的进一步 口音修正:
- source 语音在带有口音(e.g. 咖喱味的英语)的前提下,做VC,但是 我们除了想要 target 的身份,还要 目标说话人口音(e.g. 纯正的母语英语)
- 所提到的整个网络模型,综合了 TTS 、VC、ASR 的方法,也有一种采众家之长的意思,但是麻烦的是,四个模型部分,需要分别训练
综述
- 传统的口音转换:
- 内容(content)、发音(pronounciation) 不变
- 把 本地source说话人 的口音(accent),转换成 非本地target说话人 的口音
- 本文尝试source非母语:北印度人说的英语口音—>北美正统英语口音
- 传统的局限:做转换时,需要具备的条件:
- 需要有 印度人说的英语 作为source
- 需要有美国人说的英语作为 target
- 这导致了,在实际上也用途时,很臃肿难用
- 本文想法:
- 在转换阶段,提出 端到端 方法,使得不需要 美国人英语target 也能做正确的 AC (accent conversion)
- 贡献点:
- 说是目前为止第一家实现在 转换阶段 不需要目标(美国target英语语音)就能实现转换的方案
- 细化实现了对 韵律特征 的建模:(例如说话速度和持续时间)
- non-parallel
网络结构:(四部分)
- a speaker encoder
- a multi-speaker TTS model
- an accented ASR model
- a neural vocoder
- encoder 部分作用:生成speaker-embedding
- TTS 部分 用的是tacotron2(音素 + embedding 预测 mel)
Speaker encoder
- 引用的模型:

- 作用是:生成 speaker-embedding,用来和 TTS 结合,保证了生成语音 和 target 说话人 身份一致(类似VC和TTS结合?)
- GE2E(generalized end-to-end)speaker verification loss
- Baseline训练过程:
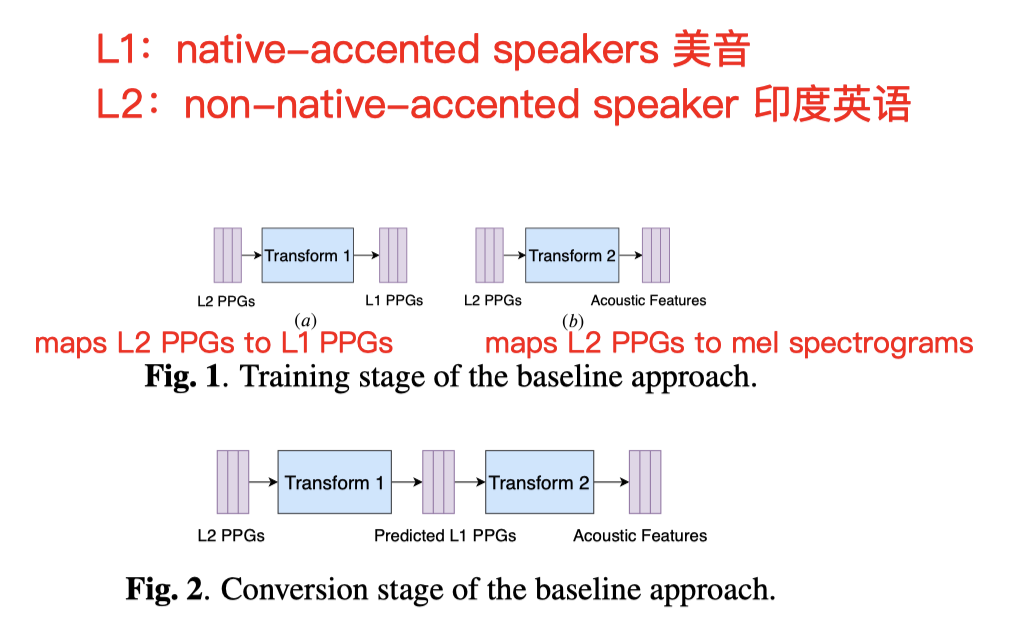
- 训练阶段训练两个转换模型:(DTW)
- Trans 1 : 将 印度英语 的ppg 和 美式英语 的ppg 利用 DTW 做对齐
- Trans 2 :将 印度英语 的 ppg 和 mel谱 做对应匹配
- 转换阶段:
- 输入 印度英语到 Trans1
- 得到 美式英语ppg
- 将ppg 继续送入 Trans2,得到对应的 mel谱
- 用wave-Net 生成语音波形
Multi-speaker TTS model && Multi-task accented ASR model
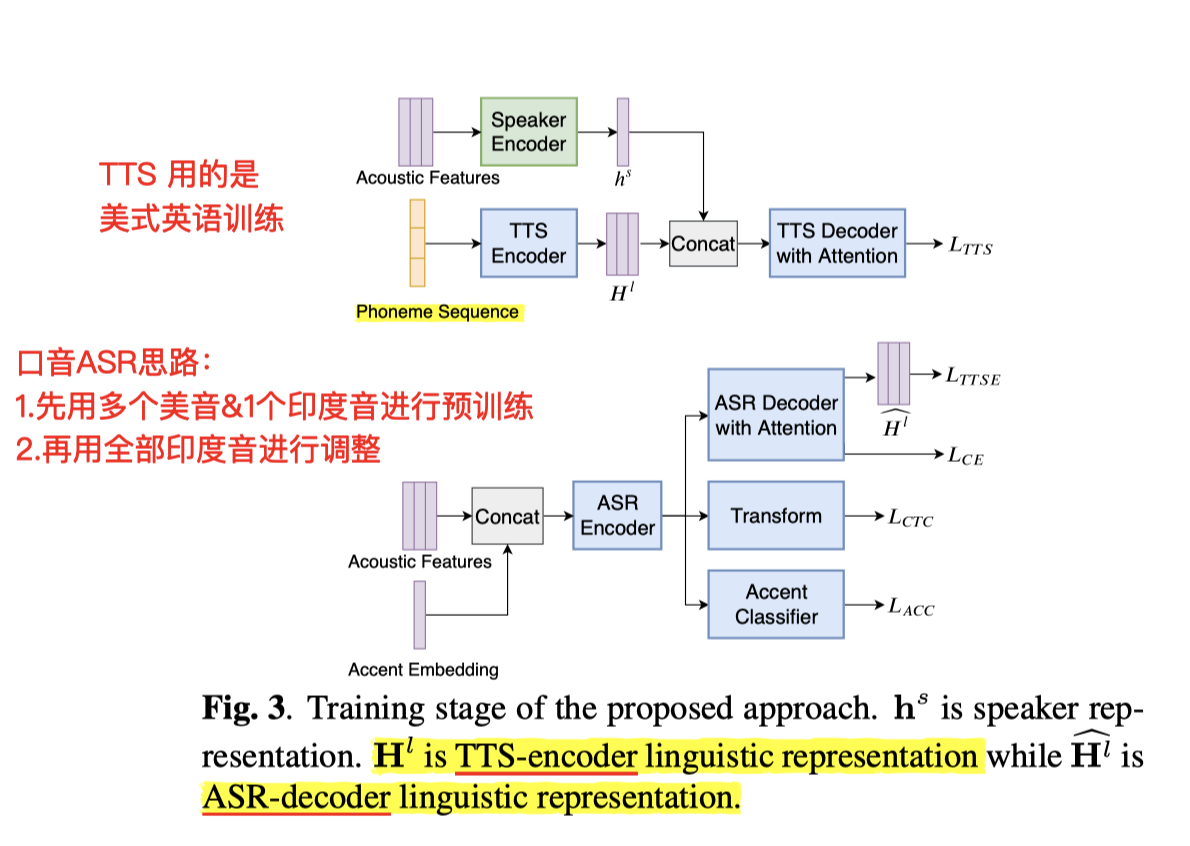
- 其中的TTS网络,摘用的这篇:(attention-based encoder-decoder model)

- text transcripts into phoneme sequences:TTS 中用phone 序列,加速收敛过程;
口音识别:Multi-task accented ASR model
训练思路:
- 前面有,用单说话人(美式英语)训练好的 speaker encoder
- 接着有 用全部都是(美式英语)训练的 多说话人 TTS 模型(TTS-loss)
- 在上面两个步骤基础上,本环节 用多个 美式英语 && 一个 印度英语 一起进行 多说话人 预训练
- 完成之后,再 全部 换成 印度口音英语多说话人 进行调整
实践中的细节:
 )
)
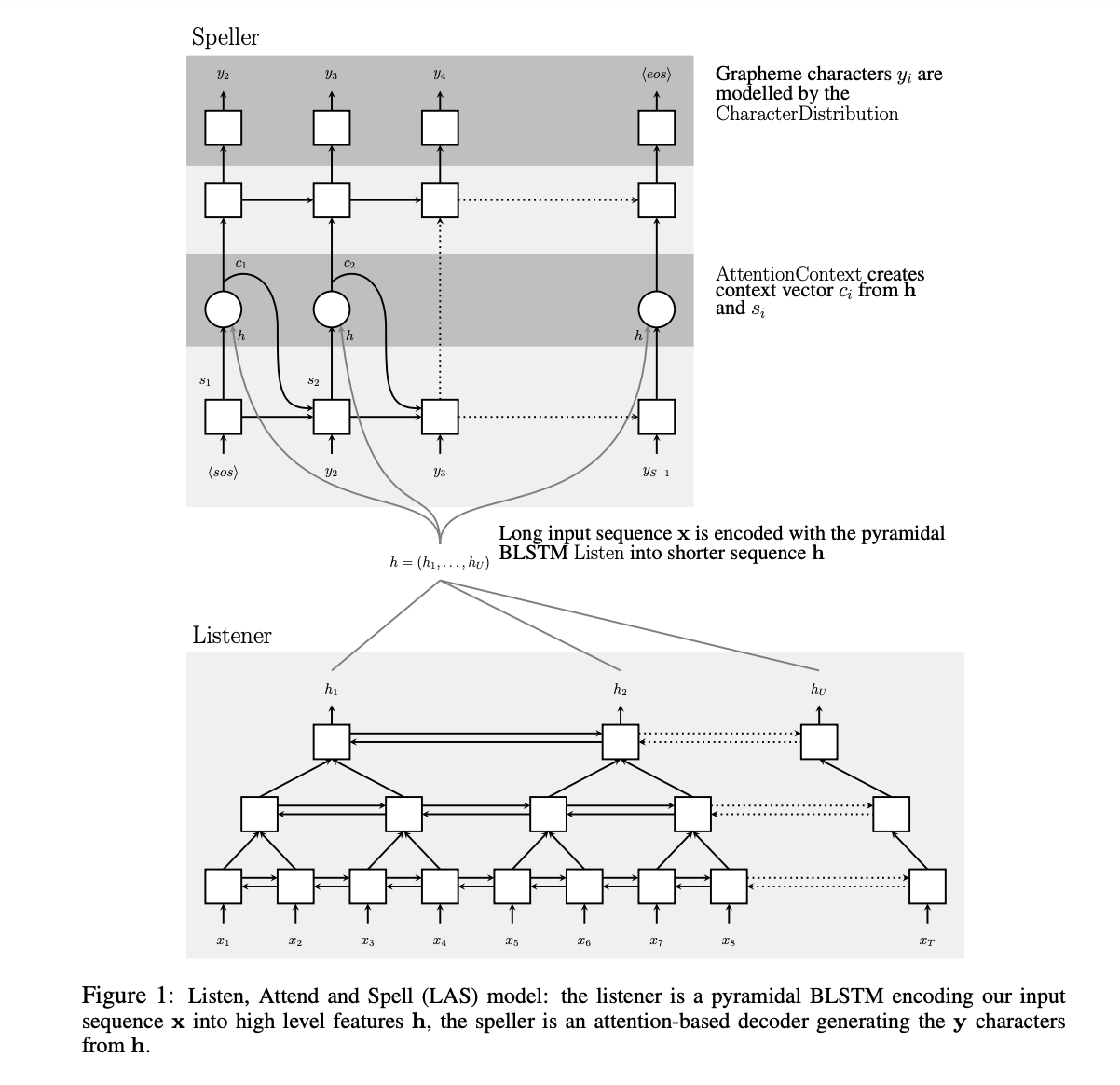
结构上:
- E2E attentioned encoder-decoder 结构:如上图(引用以前的文章思路)
改进 1 :
- 为了增加 训练稳定性,参考了文献:

- 在 Encoder 之前,增加了一个 全连接,并增加了一个 CTC loss
改进 2 :

- 在口音问题的思路上, 借鉴这篇论文:
- 在送给 ASR 之前,每帧 都concate上一个 accent embedding(这是由第一个步骤 speaker encoder 里面产生的 speaker-embedding 做一个 对单人所有语音的embedding整体均值 的结果)
- 并且在ASR的encoder最开始,再增加一个 accent classifier 口音分类器(上一步已经加过一次 FC 了);这也能使面对口音时,有更好的健壮性
🌟 Loss 环节
λ 1= 0.5, λ 2= 0.1, λ 3= 0.5 and λ 4= 0.1
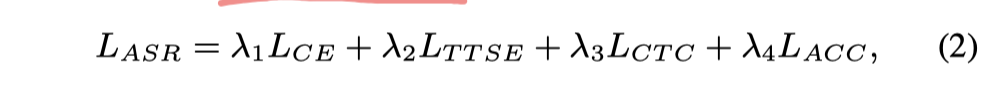
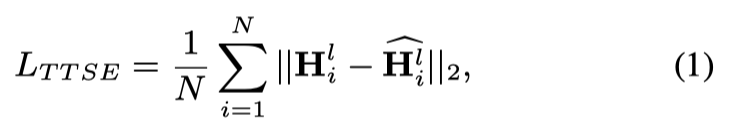
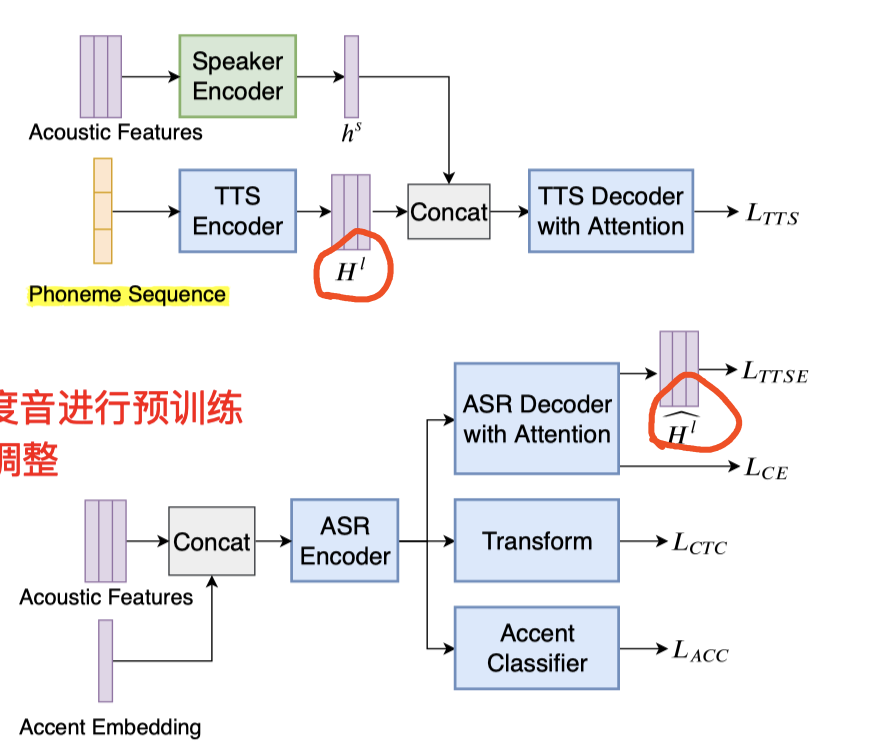
- TTSE-loss:MSE损失,对象是:1⃣️上一步已训好的 TTS 产生的声学序列(美式英语) && ASR识别出的声学序列 做一个 均方差损失
- CE-loss:phoneme label prediction (phone音素 的标签预测损失)
- ACC-loss:口音分类器的损失(类似stargan-vc里面的 speaker-classifier)
4. 后端声码器
- 本文直接采用开源的 WaveRNN
- 没有额外加任何的embedding信息,觉得说 mel频谱已经能包含所有需要的声学细节了
- 语料:全部采用 美式英语 数据来训
5. 转换阶段
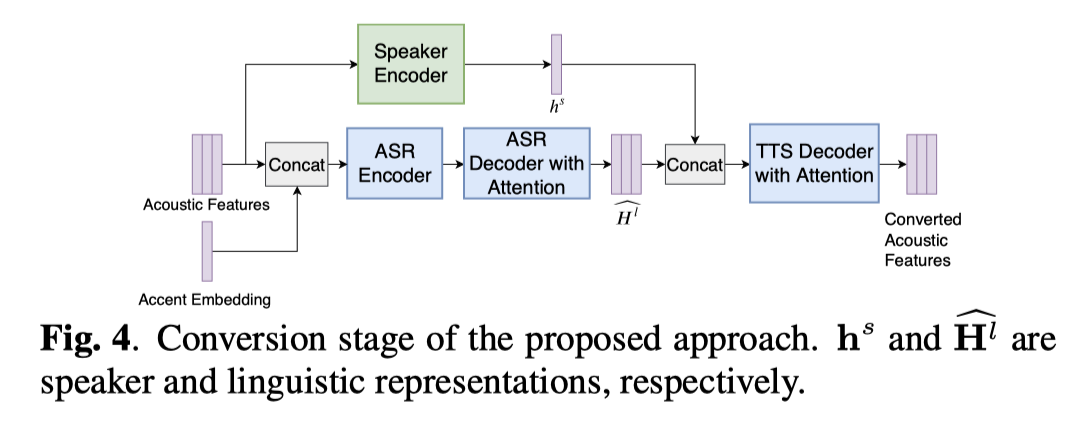
- hs:一段语音,经过 speaker-encoder之后得到的 speaker-embedding
- accent-embedding:针对同一个人的所有语音,做所有的 speaker-embedding的 均值(多个语音理解为多个通道计算)
- (Accent embedding is the averaged speaker embeddings of the non-native-accented speaker.)
- 注:accnet-embedding 是 逐帧都要插入,speaker-embedding 是最后再concate上
一些实现参数细节
5.1部分(不复赘述)
结果
(笑容满面实验,是去掉 accent embedding 和 accent classifier)
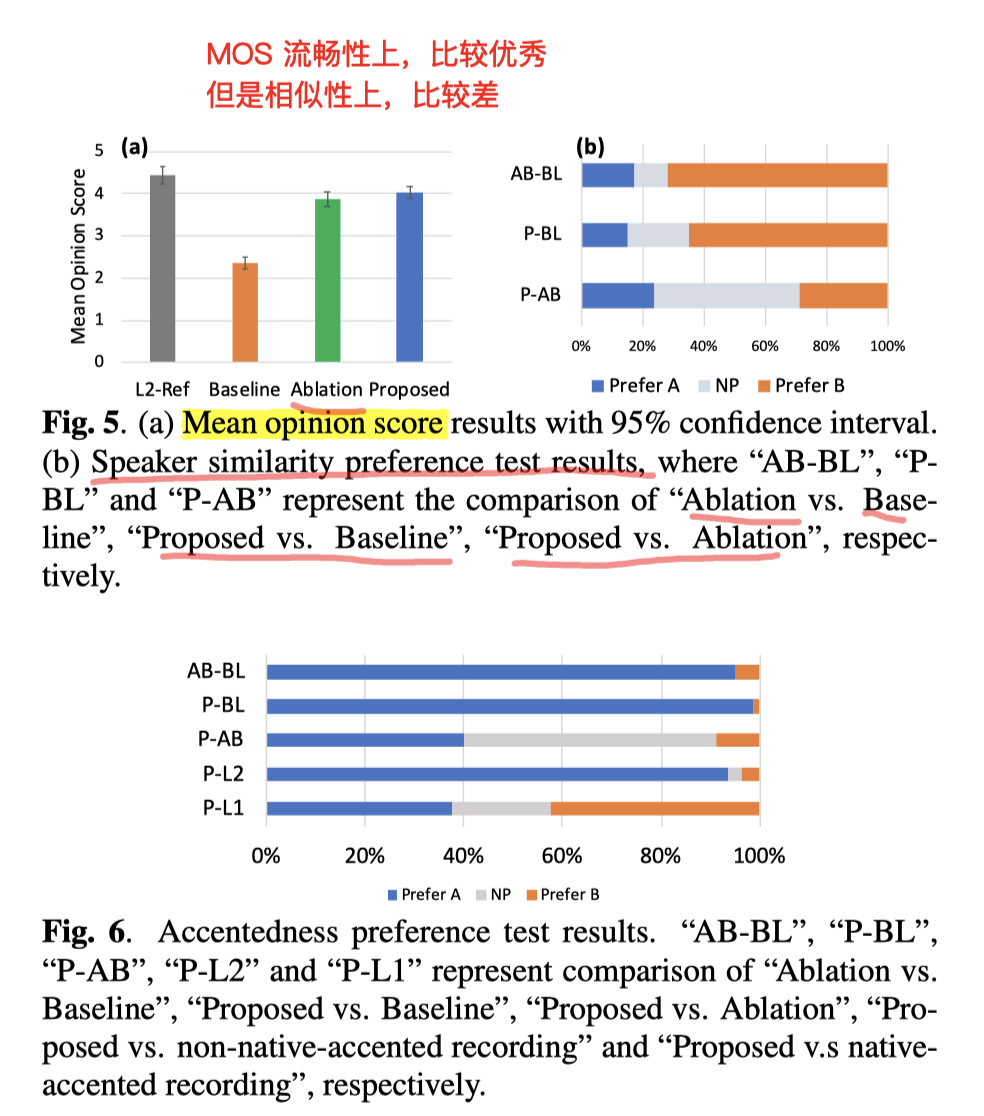
MOS得分很高
相似性上,比baseline差很多(作者猜测是数据量还是不够大的缘故)
(但他们用的VCTK 比 VCC 的几十条还是多很多的)