NVAE
先大致搞清楚 VAE
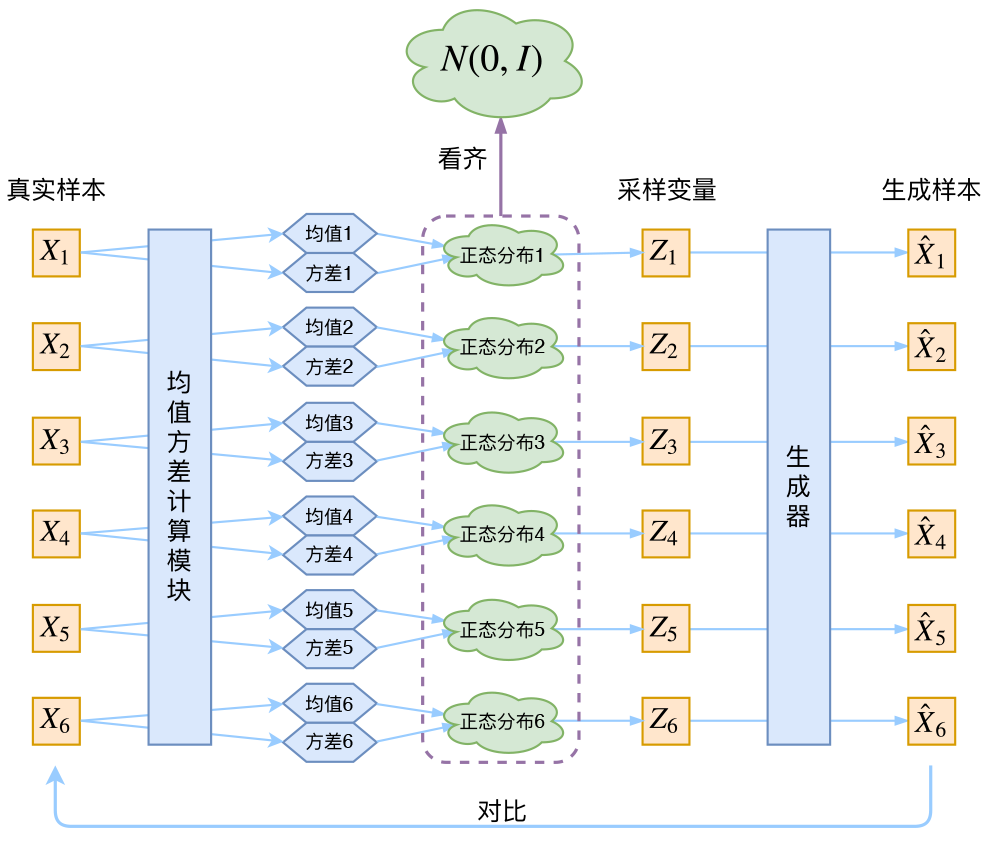
有两个 Encoder,一个求 $\mu$, 一个求 $\sigma$
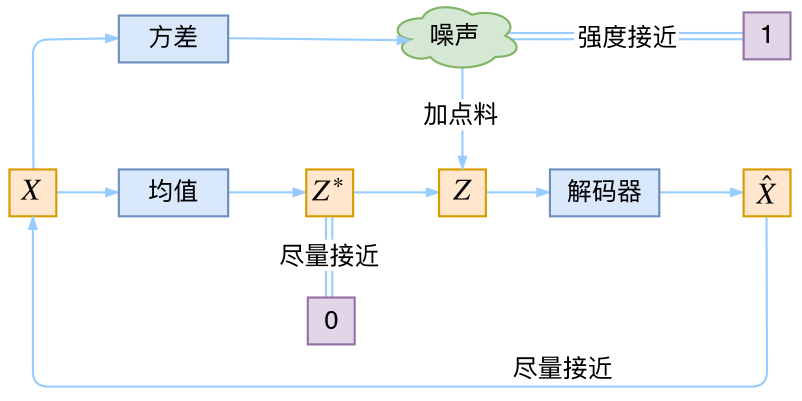
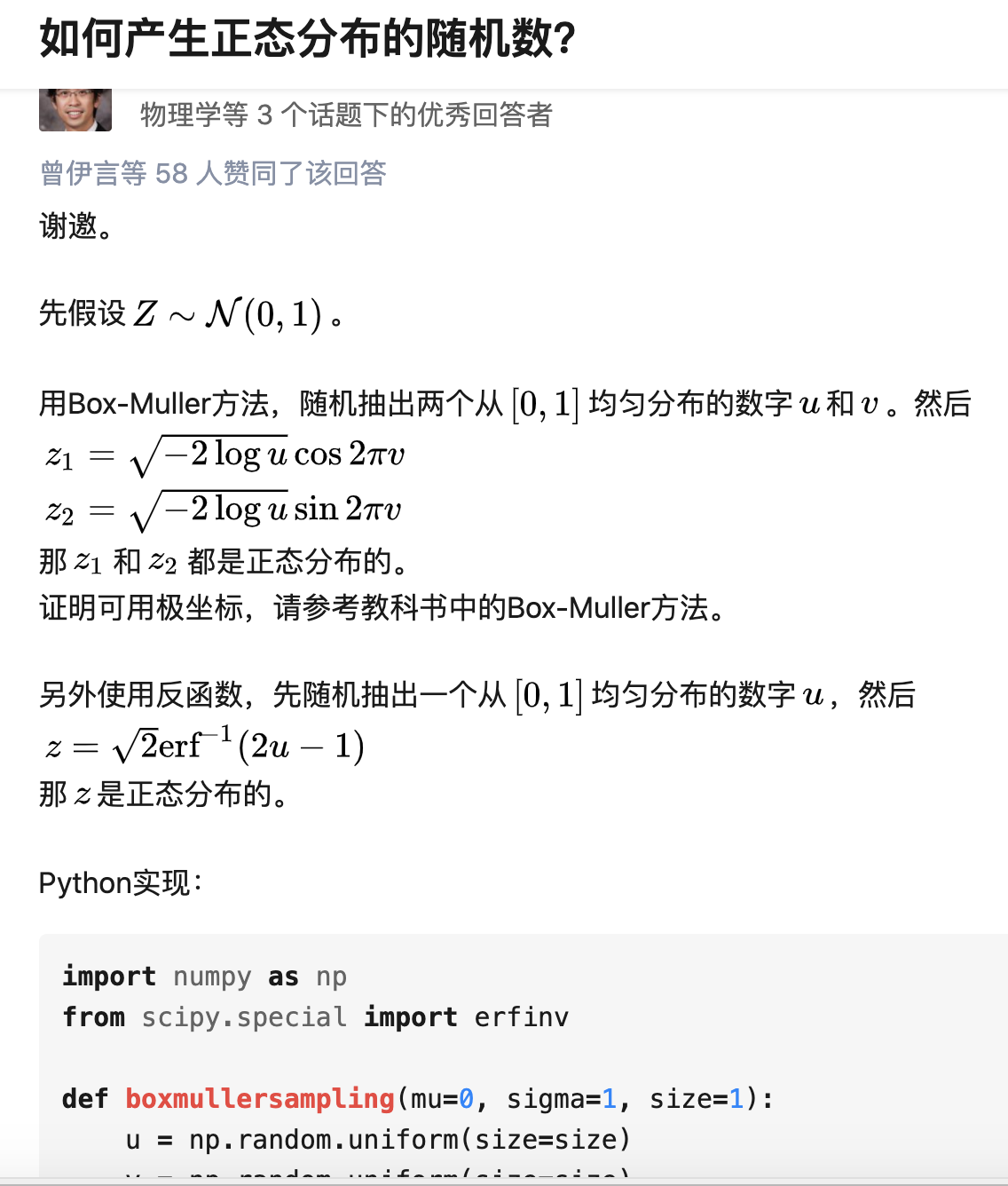
说一下 VAE 中的「正态分布拟合」以及「从拟合的正态分布中采样」(Box-Muller 等等方法)
VAE的名字中“变分”,是因为它的推导过程用到了KL散度及其性质
说一说 VAE中的噪声(方差)
- 增加重构难度,所以想减小它,让生成的数据更清晰
- 但是正是这个噪声,才是VAE精髓,增加了随机性
噪声的好处(增加随机性) 和 坏处(导致采样结果成为确定性结果——均值 u )
对噪声的处理:
- 不直接让 方差 变为0(导致退化成 AE )
- 而是配合着,让每段语音数据的 后验分布 朝着正态分布区靠近

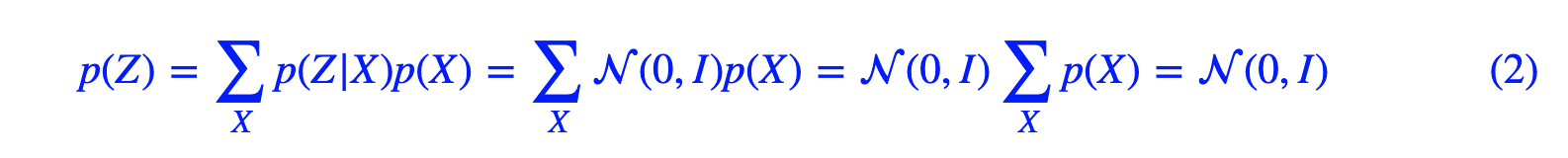
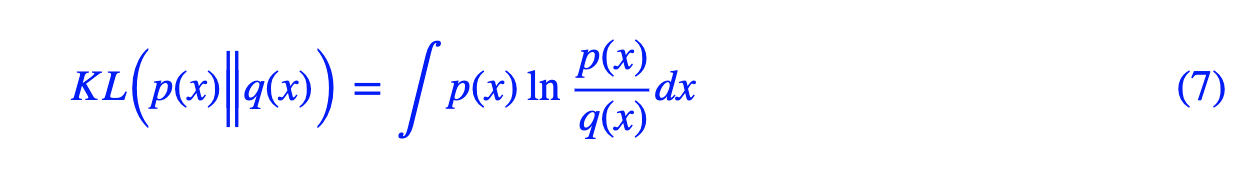
关于 后验分布 && 先验分布 的理解(公式(2))
- 后:单独的一段语音的高斯分布(标准正态)
- 先:某个说话人,所有语音的高斯分布集合(也是符合标准正态)
VAE 中的 KL-loss
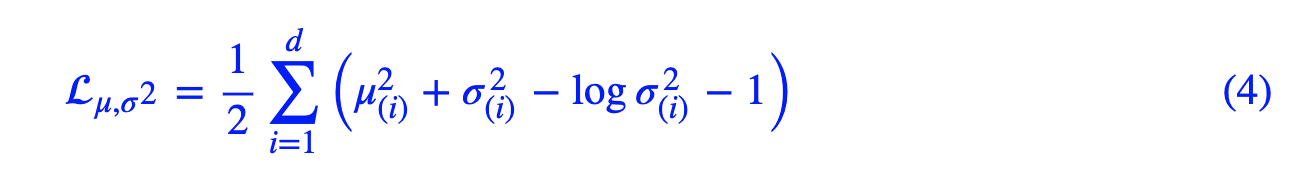
CVAE中的KL-loss(一类方法:实现标签的加入,从 无监督 转为 有监督)
 我们可以希望同一个类的样本都有一个专属的均值 $μ^Y$, (方差不变,还是单位方差),这个$μ^Y$让模型自己训练出来
我们可以希望同一个类的样本都有一个专属的均值 $μ^Y$, (方差不变,还是单位方差),这个$μ^Y$让模型自己训练出来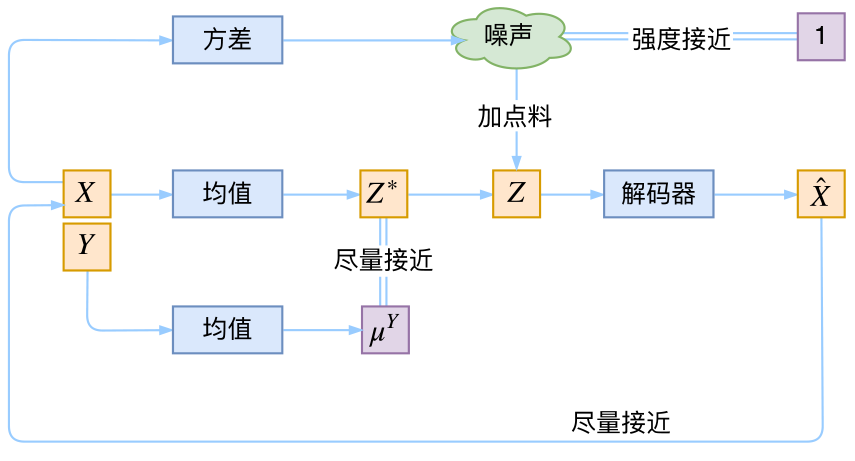 【CVAE结构图】
【CVAE结构图】
1 | python preprocess.py --resample_rate 16000 \ |
1 | python main.py --train_data_dir ./data/VCTK-Data/mc/train \ |
1 | python convert.py --resume_model 120000 \ |