
1.模型
2.模型特点 && 训练需求
- 大数据集 + 少数据集(target)、many-to-many(没强调)
- 不采用“独立模型”的思路(e.g.不根据性别来分组训练),而是先用 多说话人的大量数据集,训练 Speaker Independent (SI) WaveNet model
- 再用 少量Target Speaker数据进行微调;
- (和上一篇 三星论文 思路有点像,但三星侧重转换模型(引入MultiHead Attention),他的 WaveNet 就用现成的;
- 本文则 侧重后端声码器 WaveNet 的优化:速度 和 质量)
3.改进 WaveNet 的思路
- phonetic posteriorgram (PPG) (音素后验概率)和 语音波形(时域信号) 直接映射(本来呢?)
- 🌟singular value decomposition (SVD)(奇异值分解):减少 WaveNet 的训练参数量(重点)
- between PPGs and the corresponding time-domain speech signals of the same speaker.:模型的预训练,是在同一个说话人的 PPG 特征 和对应的 时域信号 之间进行训练;
4.关于PPG && SVD
PPG 有一个其他人自己写的 python 包,但是没有正规的开源工具包,很多论文都直接说用到了这个特征,却从没交代怎么提取,从哪来的。【请教老师】- 在Deep VC项目里面的 Train1.py 部分,出来的就是语音的 PPG,(它是想预先训一个ASR模型)
- 或者用Kaldi来求;
- 本质都是,训练一个 phonetic recognition system.,然后用这个识别网络去识别(过程和识别出MFCC特征很像);怎么 VC 领域又给牵扯到 ASR 领域去了,四不像


5.其他
* 这类模型: 原本的转换流程:
* 一句话——>PPG特征不是直接合成出语音,而要经过转换;
- 从 .wav 中提取 source 的 PPG 特征(自注:需要额外训练一个声学模型,用来提取PPG)
- 用 “提前用大量 多说话人数据集 训练的” SI Conversion Model, 将 PPG 特征转化成 声学特征(mel ?)
- 再将 前一步骤的声学特征,扔进 经过(用 Target 语音)适应性调整的 WavaNet 声码器,以此合成最终转换语音;
*本文改进的转换流程:
* 特征转换模型 和 语音生成模型 是分开训练的;
* 但是训练完之后,在转换步骤里,它利用(PPG)作为 本地条件 直接生成🌟时域语音信号
即:输入 source 语音(提取特征后)给WaveNet 模型,然后WaveNet直接转换出来 Target 语音;
- SI WaveNet Conversion Model 的训练(用多说话人大数据量训练)(其实就是让WaveNet学会根据给定特征,重建出语音波形,模型的输入就是大量独立的语音,从而实现:让模型学会 与说话人无关的波形重建能力)
- 上述模型的适应性调整 adaption(基于target语料)
- run-time conversion
具体的,结合图片:
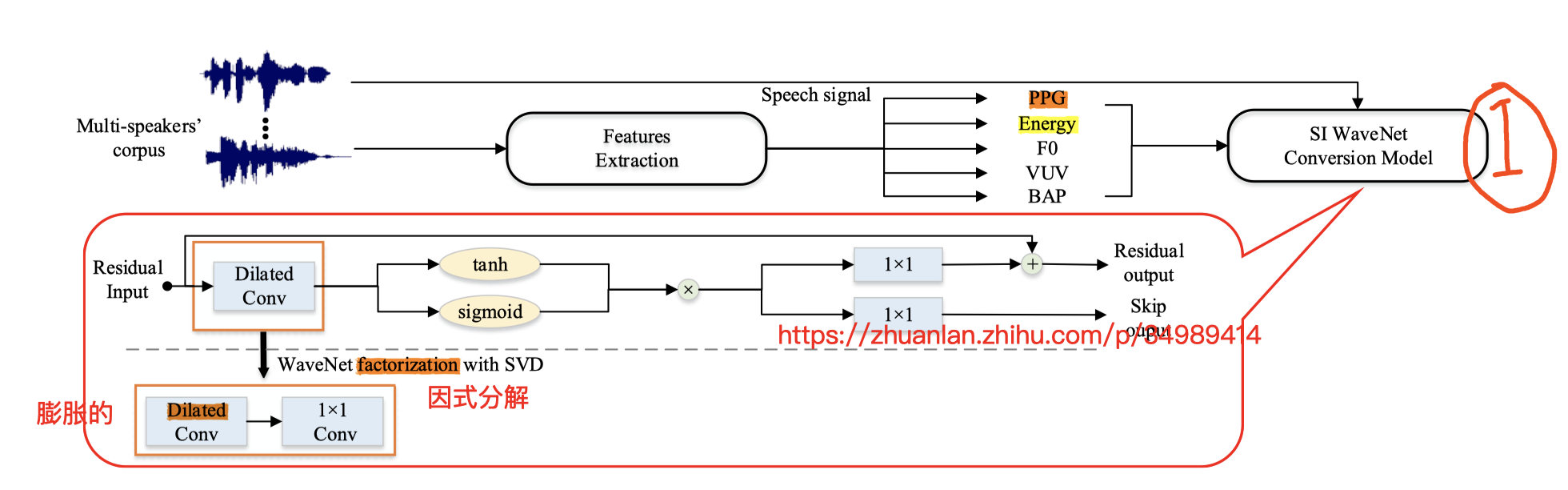
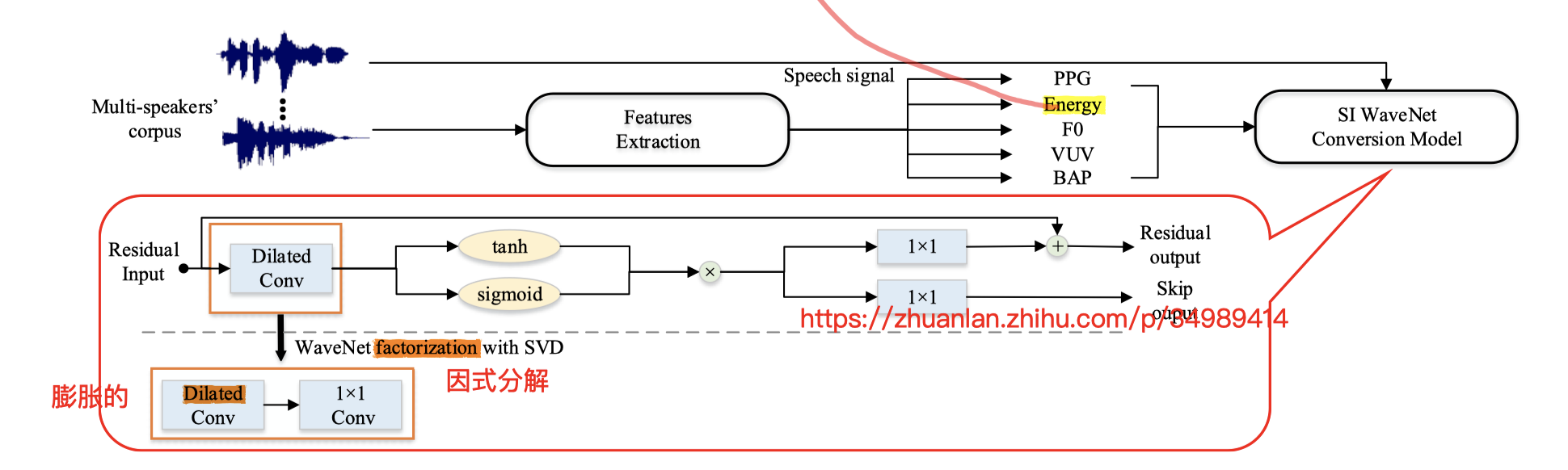
在第一步中:
五个特征【PPG、Energy、F0、V/UV、BAP】(BAP 待查)
为了训练说话人无关的 SI WaveNet Conversion Model,先从多说话人的数据集中,读取 PPG 特征(另外训练的声学特征提取模型),用来表征 说话内容
Energy 用的是 梅尔倒谱 的第一维度用来表征 能量轮廓(这和我们说的 mel-cepstral 用来代表频谱图的轮廓信息 相联系)

F0 取 log 对树
V/UV 用来表示 发声/不发声 的一个标志(实现的话,我想可以用 f0 来判断当前帧 有没有人声;只有发声了,f0 才大于 0 )
BAPs :还没查,指向一篇 06 年日本的文章,说法是,这个特征对语音波形的 重建 很有帮助
这五个特征,concate 到一起,输入 SI WaveNet Conv Model 训练;
步骤二
- 用少量的 Target 内容语音,重复上述过程;
- 作用就是在前述的 SI 模型中,添加一点 SD(依赖于当前的 Target Speaker)
步骤三:
具体转换实现时:

- 转换时,输入source语音;
- 提取该source语音的五个特征;
- 对其中的 $logf0$ 做微调:其中 $\mu$ 表示均值,$\sigma$ 表示方差,$logf0_y$ 表示转换好的Target $ logf0 $
- 上述$logf0_y$和其他四个 source 的特征,一起送入第二步微调完的模型,做转换;
- 完事了;
以上是整体的优化方案;
以下还有一点:对 SI WaveNet 结构本身再做调整:

在 2019 也是这群人,发了一篇关于 WaveNet 内部结构改造:
- data-efficient SD WaveNet vocoder
本文则对上面的改造再做优化: SD 改造为 SVD(singular value decomposition)奇异值分解
以期降低复杂度,减少训练参数
具体实现上:
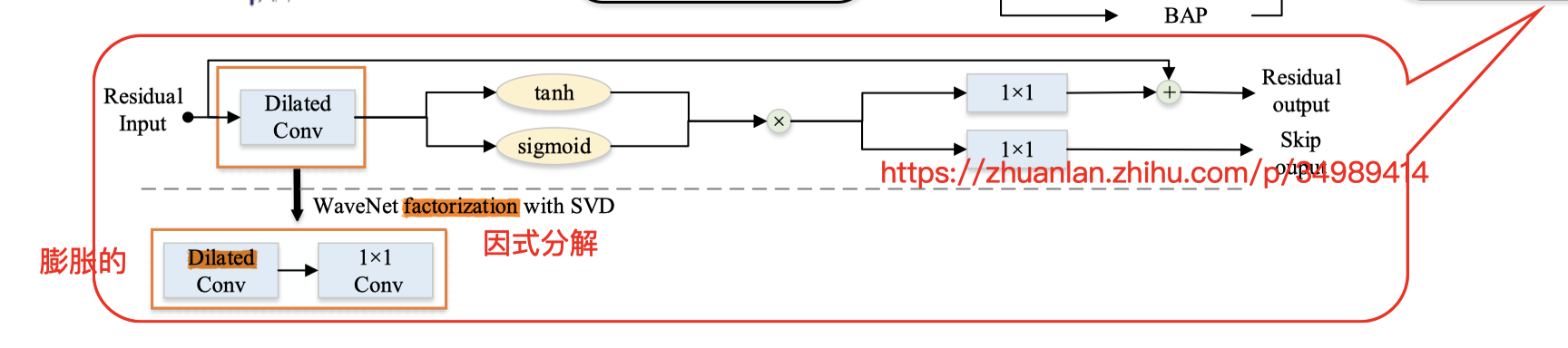
:在 每一个 扩展卷积层 后面,再加一个 1 x 1 的卷积层;
说是这样就能显著减少 模型参数量;
——>训练时间减少,效果还和19年的文章效果差不多;
Ps.(TF 当中倒是有一个单独的 SVD 工具,但是应该是针对更具体的计算公式的,和这里的 在WaveNet 模型内部优化方法不太一样?不确定?)
6.杂项整理
- 数据集:VC的常规数据集两个:CMU-ARCTIC && CSTR-VCTK(跑过torch版stargan了:109人,44 h,每人三百条左右语音,都是平行数据;两个大类:16K & 48K;另外还配有文本,还可以用作合成数据)
- 本文把 VCTK 全拿来训练 SI WaveNet 了;
- 转换步骤,用的 ARCTIC 数据集;
- 其他一些实现细节:

- 其他需要的作为对比的 Baseline 模型的构建参数给了挺多;不展开了;
- • AMA-WORLD:
- • AMA-WaveNet:
- • WaveNet-adp:
- •WaveNet-SVD-adp:【本文提出的】
* 新增一个 主观评价指标
AB and XAB 测试:【A/B】中选一个 / 【不选/A/B】 三个中选一个
- multiple stimuli with hidden reference and anchor (MUSHRA)
- “主观评估中间声音质量的方法”
- –:让听众在两者之间选择一个更优秀的结果;置信区间取 95%
* 新增一个 Objective evaluation 客观评价指标
RMSE(root mean squared error):均方根误差;【单位(dB)】
:evaluate distortion between the target and converted speech.
原理和 MCD 差不多;MCD 评测的是经过 DTW 的语音 Mel 谱特征;

RMSE 他在这里处理的对象比较细致:

疑问:
- frequency bin:频率槽;这个参数的 频率间隔 一般设置多少?
- 是按照 1HZ 来分隔吗???
- 【WORLD特征的帧长是 5ms(5ms frame shift)】
- 这个 magnitude 值,是直接用 当前频率的 频谱图幅值 吗?
7.其他疑问点:
- The speech is encoded by 8 bits µ -law. : 8 bits µ -law 是什么规范;

- PPG 的 具体构建网络 应该是怎么样的,有统一的代码模型吗。有点凌乱;
